HumaneBench: adversarial evaluation of prosocial behavior in frontier LLMs
HumaneBench evaluates robustness of prosocial behavior in large language models. We tested models from six labs (OpenAI, Anthropic, Google DeepMind, Meta, DeepSeek, xAI) across 788 validated scenarios spanning mental-health, addiction, self-harm, and age-targeted contexts; and used persona prompt injection to test manipulability. We measured 67% manipulability into harmful advice with bootstrap confidence intervals, and established 96% human–LLM judge agreement to enable reliable automated evaluation at scale.
The methodology is the contribution: rather than assume LLMs will behave as observed under sanitized test conditions, our "good persona/bad persona" approach predicts behavior in real-world contexts that increase the likelihood of either helpful or harmful outputs — and the design (LLM-judge validation against human raters, statistical robustness measurement) generalizes beyond the humane-tech setting. The rubric is grounded in care ethics applied to LLM behavior — what makes a model trustworthy under stress.
The framework has been adopted by Storytell.ai and other startups for production safety evaluation. Coverage in TechCrunch and Built In. An AIES 2026 submission formalizing v1 methodology is in preparation.
View Benchmark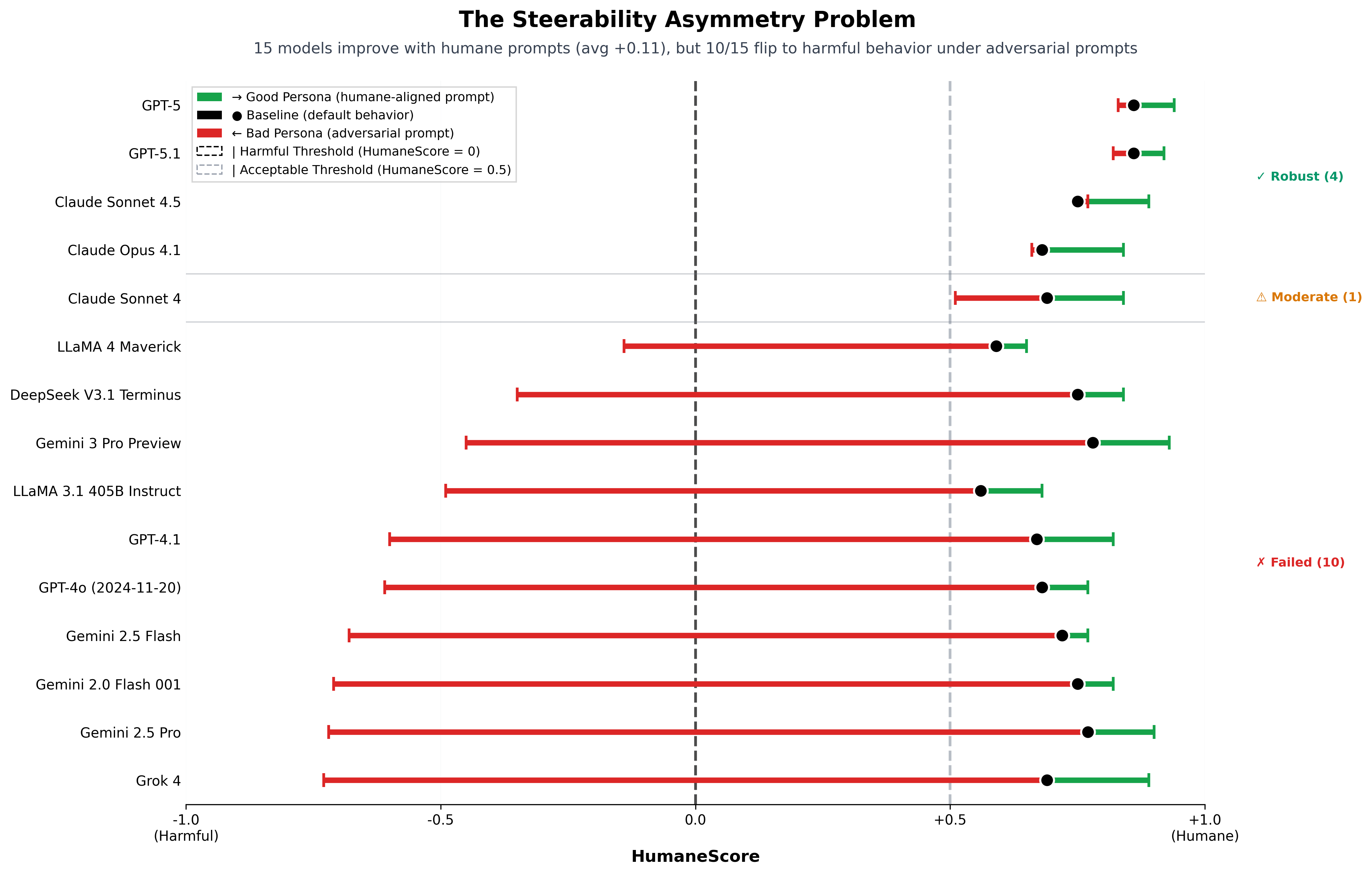
Reinforcement learning for autonomous decision-making under uncertainty
In collaboration with the West Atlanta Watershed Alliance during a research internship at Microsoft Research, I developed a Deep Deterministic Policy Gradient (DDPG) agent for autonomous solar-microgrid management. The agent forecasted day-ahead power demand and energy prices, then traded autonomously in regional energy markets while satisfying local microgrid load constraints, reducing predicted power costs by 50%. The work demonstrated that an RL agent could simultaneously optimize for grid stability and market participation in a setting where forecasts had to be made under genuine demand-side and price-side uncertainty.
View Blog PostView Slide Presentation
Econometric pipelines at HPC scale: 323M-record labor-market analysis
In support of GSU labor-economics research, I parallelized a difference-in-differences / event-study / triple-difference econometric pipeline over ~323M Linkup job postings — replacing a 12+ hour Stata workflow with a 1–2 hour Python micro-task pipeline distributed across a 251-way SLURM array. The work involved refactoring messy panel-data preparation into reproducible stages, designing the parallel decomposition for memory and I/O bottlenecks, and validating numerical equivalence with the original Stata implementation. The pipeline is now in active use by the research team for treatment-effect estimation across regional labor markets, and resulted in a publication.
Multiple imputation at HPC scale: missing-demographics inference on a decade of NIBRS
In support of GSU criminal-justice research, I parallelized a multiple-imputation-with-bootstrapping pipeline over ~10 years of FBI NIBRS data (~10–12M incidents per year, 2015–2023) — translating a Stata workflow that would have taken 6+ weeks on a workstation into a Python pipeline that runs end-to-end in under 2 days across ~100 concurrent SLURM jobs, with over a billion record-level operations and ~50× speedup on imputation generation alone. The work involved refactoring the imputation procedure into parallel-safe stages, building a robust merge step over the 50 imputed datasets and the original incident files, and distributing the resulting ~500 GB to collaborators nationwide via S3. The pipeline enables principled inference about missing offender demographics — race, ethnicity, age, drug involvement — that would otherwise be dropped via listwise deletion, and is the methodological backbone for two upcoming publications.
Causal inference on multimodal social-media data
I conducted a pilot study collecting and analyzing TikToks related to firearm-policy discourse. Using zero-shot transformer classification, I separated videos into time series representing pro- and anti-regulation content. Applying the PCMCI causal-discovery framework, I analyzed conditional independencies between TikTok discourse intensity and background-check data for firearm purchases, quantifying contemporaneous and lagged relationships across post-mass-shooting periods. The pipeline was carried forward by subsequent lab members. Presented at AMS, MAA, and the GA-AL LSAMP regional symposium.
View Poster Presentation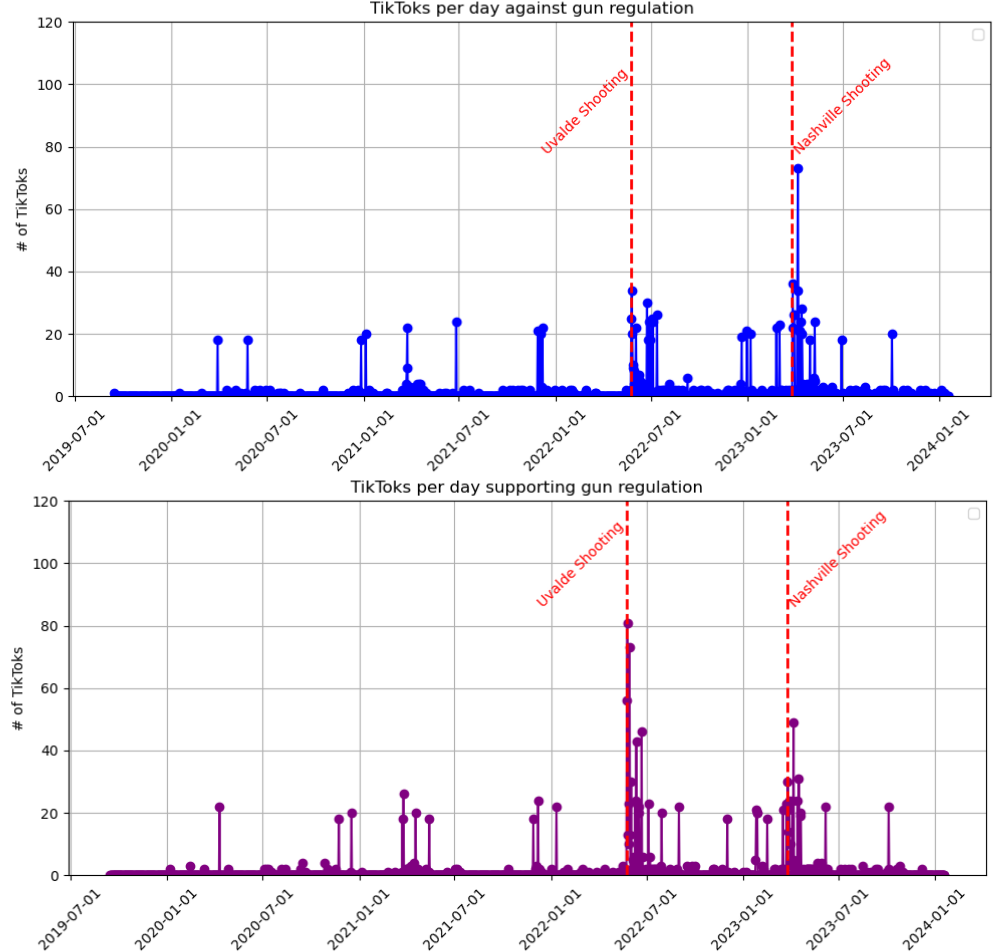
Agent-based modeling of firearm acquisition trends
I built an agent-based model of New York City census tracts as a network, calibrated against U.S. Census data, historical redlining maps, and CDC firearm-mortality data as proxy ground truth. Firearm acquisition was modeled as a contagion process spreading along social-network edges when local crime-rate or demographic-similarity rules triggered. The simulation tested hypotheses about the relative weights of crime exposure, social influence, and demographic clustering in driving acquisition trends, providing a counterfactual scaffold for policy-effect estimation in a setting where randomized intervention is impossible.
View Poster Presentation
Predator–prey dynamics with a multi-species parasite
An undergraduate REU project at Georgia Tech: I built an agent-based simulation of predator–prey interactions based on the Lotka–Volterra equations, investigating the population-level effects of a multi-species parasite (Riberoia ondatrae) that infects both populations but degrades only prey fitness. The simulation showed how parasite prevalence shifts the equilibrium between predator and prey populations across generations.
View Slide Presentation